lucene基本使用
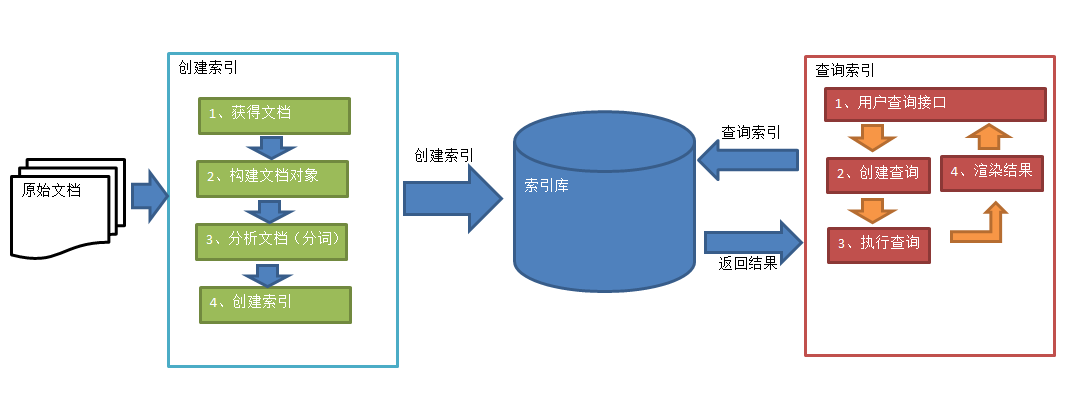
lucene主要用于对非结构化数据的解析,常见的非结构化数据例如:邮件、doc文档、pdf文档等等,lucene技术就是将这些非结构化数据解析整理成具有一定结构化的数据,lucene的基本使用主要分成下面几方面
- 索引库的建立:将非结构化数据分析整理成具有一定结构化的数据,并创建索引库
- 索引库的内容的增删改查
索引库的创建
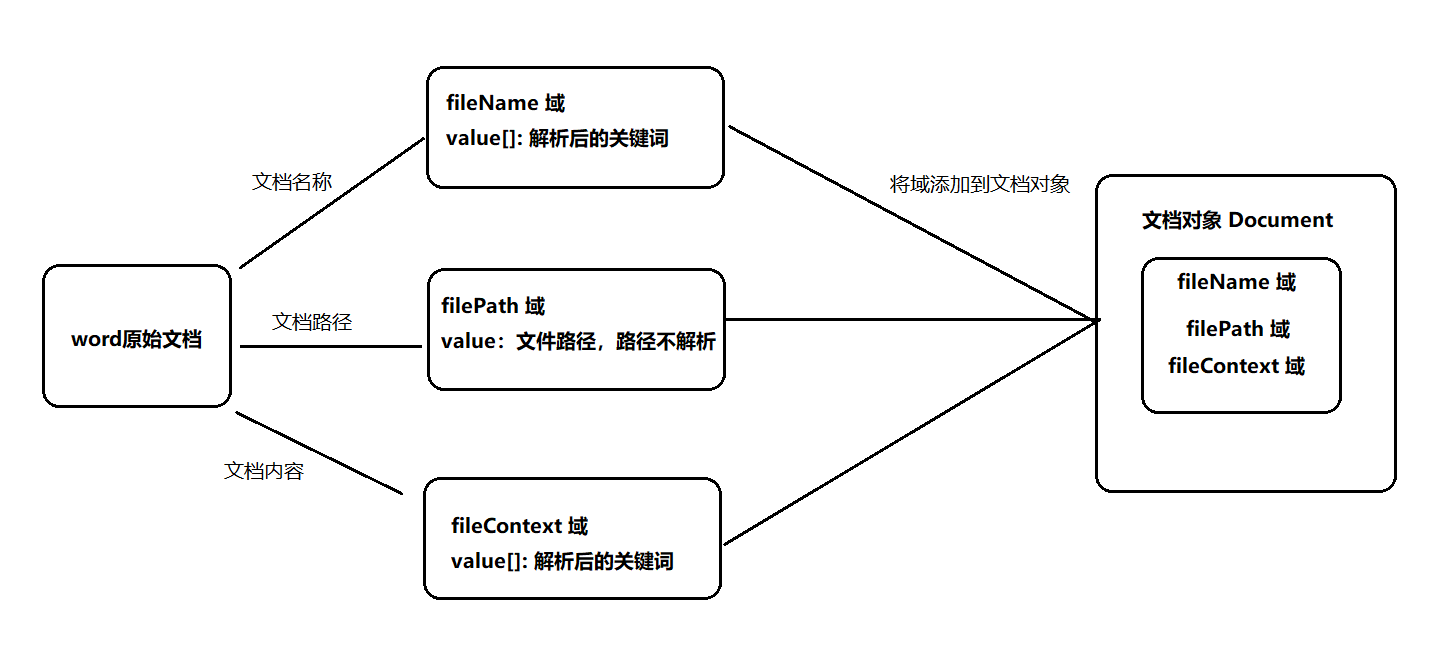
创建索引的过程就是将原始文档的内容解析成多个域,例如解析一个word文档,将文档的名称传到文件名称域里面解析成多个关键词,将文档里面的内传到内容域里面解析成多个关键词,解析后的关键词都存储在域里面,然后将这几个域添加到一个文档对象里面,这就是原始文档到文档对象的解析过程。
下面是创建索引库的实现步骤
1、引入依赖
1 | <dependency> |
2、代码实现
1 |
|
3、Field域的属性
上述几个用到的几个域的属性详细说明如下
| Field类 | 数据类型 | Analyzed 是否分析 | Indexed 是否索引 | Stored 是否存储 | 说明 |
|---|---|---|---|---|---|
| StringField(FieldName, FieldValue,Store.YES)) | 字符串 | N | Y | Y或N | 这个Field用来构建一个字符串Field,但是不会进行分析,会将整个串存储在索引中,比如(订单号,姓名等) 是否存储在文档中用Store.YES或Store.NO决定 |
| LongPoint(String name, long… point) | Long型 | Y | Y | N | 可以使用LongPoint、IntPoint等类型存储数值类型的数据。让数值类型可以进行索引。但是不能存储数据,如果想存储数据还需要使用StoredField。 |
| StoredField(FieldName, FieldValue) | 重载方法,支持多种类型 | N | N | Y | 这个Field用来构建不同类型Field 不分析,不索引,但要Field存储在文档中 |
| TextField(FieldName, FieldValue, Store.NO) 或 TextField(FieldName, reader) | 字符串 或 流 | Y | Y | Y或N | 如果是一个Reader, lucene猜测内容比较多,会采用Unstored的策略. |
查询索引库
1 |
|
删除索引
1、删除全部索引
1 |
|
2、删除指定索引
1 |
|
增加索引
新增一条索引的过程跟创建索引库的过程差不多,差别只在于增加索引只需要对一个原始文档进行解析
1 |
|
更新索引
更新索引的过程就是先删除该文档的原始索引,然后再创建一条该文档的新索引
